

آموزش یادگیری ماشین را از کجا شروع کنیم؟
برای شروع یادگیری ماشین باید از پیشنیازها و مفاهیم آن اطلاع داشته باشید و حتما به یک زبان برنامهنویسی مناسب مسلط باشید. به همین دلیل نقشه راه یادگیری ماشین را برای شما ترسیم کردهایم تا طبق آن به یک مهندس ماهر در این حوزه تبدیل بشوید. البته در نظر داشته باشید که شما میتوانید هر مرحله از این نقشه را مطابق با نیاز و موقعیت خودتان تغییر بدهید.
-
پیش نیاز یادگیری ماشین
معمولا بهتر است قبل از ورود به حوزه یادگیری ماشین، در موارد زیر مسلط باشید:
- جبر خطی
- ریاضی و حسابان
- آمار و احتمالات
و یک زبان برنامهنویسی را آموزش دیده باشید، که در ادامۀ همین مطلب، بهترین زبان برنامهنویسی برای یادگیری ماشین را به شما معرفی خواهیم کرد.
همچنین توجه داشته باشید که اهمیت تسلط شما بر هر کدام از موارد فوق، ارتباط مستقیمی با نوع فعالیتتان در حوزۀ یادگیری ماشین دارد. به عنوان مثال اگر در تیم تحقیق و توسعه “R&D” یک شرکت هستید، باید کاملا بر این مباحث تسلط داشته باشید. چون کتابخانهها و فریمورکهای موجود به شما کمک چندانی نخواهند کرد.
-
آموختن مفاهیم مختلف یادگیری ماشین
شما در آموزش یادگیری ماشین باید با انواع مدلهای آن یعنی، یادگیری با نظارت (Supervised ML)، یادگیری بی نظارت (Unsupervised ML) و یادگیری تقویتی (Reinforcement ML) آشنا شوید. نحوه عملکرد یادگیری ماشین را بیاموزید. مهمترین الگوریتمها و موارد کاربرد هر کدام را بدانید و با نمونههای استفاده شده از ماشین لرنینگ ML در دنیای واقعی آگاه شوید.
تمامی موارد ذکر شده به تفصیل در این مقاله به شما آموزش داده خواهد شد.
-
محک زدن خودتان با استفاده از تمرین ها و داده های موجود
بعد از اینکه اصول یادگیری ماشین را فهمیدید حتما باید با تمرینهای عملی خودتان را محک بزنید.
تمرین باعث میشود دانش نظری خود را در نمونهای عملی، به کار بگیرید و مهارت خود را در ML بیشتر کنید. یکی از بهترین تمرینهایی که میتوانید در آموزش یادگیری ماشین با آن کار کنید، پروژه مسافران کشتی تایتانیک است که شما را در اکتشاف دادهها، مهندسی ویژگیها و تنظیم مدل به چالش میکشد. برای این کار میتوانید از دادههای موجود در وبسایت کگل “Kaggle” استفاده کنید.
حالا که با نقشۀ راه آموزش یادگیری ماشین (Machine Learning) آشنا شدید، با هم قدم به قدم این مسیر را طی میکنیم.

پیشنهاد دانشیار آی تی به شما
پردازش زبان طبیعی (NLP)
خواندن مطلب
یادگیری ماشین چیست؟
یادگیری ماشین (Machine Learning) دانشی است که کامپیوترها را به یادگرفتن و رفتار کردن مثل انسان وا میدارد. این سیستمها، رفته رفته که با دادهها، شبکهها و افراد تعامل دارند، به طور خودکار باهوشتر میشوند تا در نهایت بتوانند موضوعی کاربردی در جهان را برای ما تعیین یا پیشبینی کنند.
کاربرد ماشین لرنینگ در وب سایت های معروف ایران و جهان
یکی از کاربردهای ماشین لرنینگ در جهان، ارائه پیشنهادات است. مثلا وقتی اکانتی در پینترتست باز میکنید و چند تصویر را پین میکنید، از دفعات بعد تصاویری با همان مضمون را به شما نشان میدهد.
یادگیری ماشین در ایران
مثال یادگیری ماشین در ایران سایت دیجیکالا است. وقتی در دیجی کالا یک موضوع مشخص را سرچ میکنید، از دفعات بعد که وارد سایت میشوید، اجناس مرتبط با آن سرچ را بیشتر به شما نشان میدهد. سیستم این کار را بر اساس دیتای ذخیره شده از طرف شما انجام میدهد و در واقع از رفتار شما یاد میگیرد تا طبق ترجیحات و نیاز شما رفتار کند. این همان معجزه یادگیری ماشین است.
ماشین لرنینگ مشکل اصلی برنامه نویسی سنتی را چطور حل کرد؟
در برنامهنویسی سنتی، تمام قوانین (Rules) باید با مشورت یک متخصص در حوزه و صنعتِ مورد نظر، کدنویسی شود و هر قانون بر اساس یک فونداسیونِ منطقی، یک خروجی را تحویل میدهد. اما وقتی سیستم بزرگتر میشود، پیچیدهتر هم میشود و طبعا به کدنویسی بیشتری نیاز است. این امر باعث میشود سیستم خیلی زود به حدی برسد که دیگر خارج از کنترل و نگهداری باشد.
یادگیری ماشین این مساله را با یادگیری خودکار کاملا حل کرده است. سیستمی را در نظر بگیرید که بدون کدنویسی توسط برنامهنویس، خودش از مثالها یاد میگیرد و میتواند به تنهایی از دادهها، نتایجِ دقیق استخراج کند. یادگیری خودکار، مزیت اصلی ماشین لرنینگ در مقابل برنامهنویسی سنتی است.
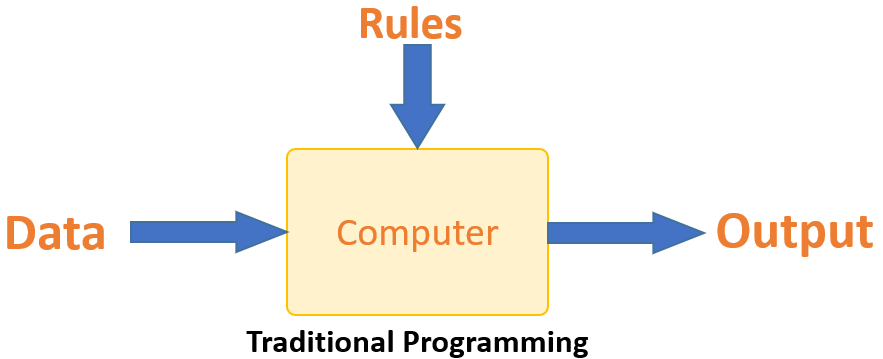
ماشین یاد میگیرد که چطور اطلاعات ورودی و خروجی، با هم مرتبط هستند و از روی همان، خودش یک قانون مینویسد. برنامهنویسان دیگر نیاز نیست هر بار وقتی دیتای جدید دارند، قوانین جدید بنویسند. چون الگوریتمها در پاسخ به اطلاعات و تجربههای جدید، هربار آپدیت و به روزرسانی میشوند و به این ترتیب در طول زمان عملکردشان بهبود پیدا میکند.

در واقع یادگیری ماشین، اطلاعات را با ابزار محاسباتی (Statistical Tools) ادغام میکند تا یک خروجی و نتیجه را پیشبینی کند. جالب اینکه ماشین از همین خروجی دوباره استفاده میکند تا به یک درک بهتر در رفتار و اقدامهای بعدی برسد.
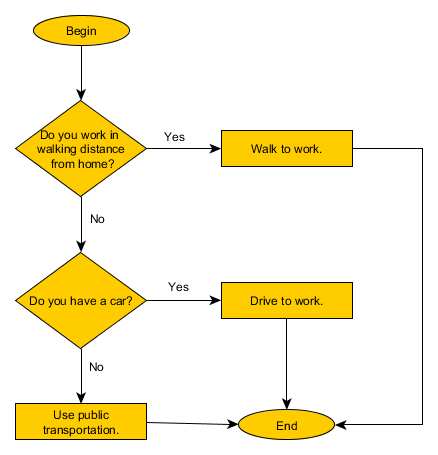
اگر شما قصد شروع یادگیری برنامهنویسی را دارید، پیشنیاز آن بدون شک الگوریتم و فلوچارت خواهد بود.
آموزش الگوریتم نویسی و فلوچارت با مثال
الگوریتم چیست؟ الگوریتم به مراحلی از یک دستورالعمل گفته میشود که باید اجرا شود تا یک مساله حل شود. فلوچارت زیر نمونۀ سادهای از یک الگوریتم است.
مثال یادگیری ماشین برای درک بهتر عملکرد آن چیست؟
بهترین مثال برای درک چگونگی یادگیری ماشین، یادگیری انسان است. انسان در یادگیری از تجربههایش میآموزد. هر چقدر ما بیشتر بدانیم، راحتتر پیشبینی کرده و تصمیم میگیریم و احتمال موفقیت ما در موقعیتهای کاملا جدید و ناشناخته، کمتر از موقعیتهای آشنا است.
ماشین هم به همین ترتیب آموزش میبیند و رفتار میکند. اول سیستم باید با حجم زیادی از دیتا و اطلاعات مناسب تغذیه شود. ما به ماشین نمونههای مشابه را میدهیم و ماشین برای اینکه یک پیشبینی دقیق و صحیح داشته باشد، به نمونههای قبلی مراجعه کرده و خروجی مناسب را تشخیص میدهد.
همچنین دقیقا مثل انسان، اگر با چیزی مواجه شود که قبلا مشابهش را ندیده است، به سختی میتواند جواب را پیشبینی کرده و خروجی مناسبی به ما بدهد. به همین دلیل دیتا نقش کلیدی در این روند ایفا میکند.
تا اینجای مسیر از آموزش یادگیری ماشین، متوجه شدیم که ماشین لرنینگ چیست، چه مزیتی نسبت به برنامهنویسی سنتی دارد و یادگیری آن چقدر شبیه به انسان است. در ادامه به جزئیات عملکرد و انواع الگوریتمهای یادگیری ماشین و همچنین موارد کاربرد هر کدام، در دنیای واقعی خواهیم پرداخت.
![]() دورههای مرتبط در دانشیار آی تی
دورههای مرتبط در دانشیار آی تی
یادگیری ماشین Machine Learning چگونه کار میکند؟
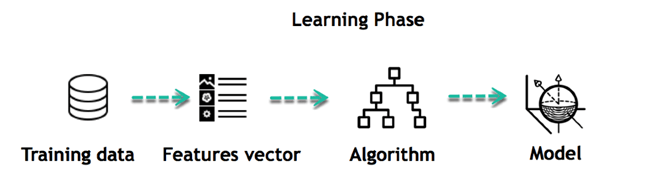
یادگیری ماشین از دو بخش اصلی تشکیل میشود: ۱- یادگیری (Learning) و ۲- استنتاج (Inference) که به ترتیب و البته در یک چرخه اتفاق میافتد.
یادگیری از داده ها؛ بخش اول در ماشین لرنینگ
در وهله اول، ماشین توسط کشفِ الگو از دادهها (Data)، یاد میگیرد. به همین دلیل یکی از مهمترین بخشها، انتخابِ با دقتِ آن دسته از دادههایی است که باید در اختیار ماشین گذاشته شود.
برای این منظور، بردار ویژگی (Feature Vector) یا همان زیرمجموعهای از دادهها که برای حل یک مسالهی مشخص، جدا شده است، در اختیار ماشین قرار میگیرد. ماشین بر اساس الگوریتمها، آنها را بررسی کرده و الگوهایی را استخراج میکند؛ سپس هر چه از دادهها کشف کرده، به یک مدل تبدیل میکند.
به عنوان مثال؛ ما دیتای اولیه از افراد شاغل، میزان حقوق آنها و تعداد دفعات رفتنشان به رستوران را تحت عنوان (Feature Vector) از دیتای آموزشی خود (Training Data) جدا کرده و به سیستم میدهیم. سپس سیستم سعی میکند تا ارتباطی بین حقوق یک فرد و احتمال رفتن او به یک رستوران فرضی را بفهمد.
ماشین زمانی به نتیجه مطلوب میرسد که یک ارتباط مثبت بین حقوق و رفتن به یک رستوران گران قیمت پیدا کند و این همان مدل مورد نظر ما است.
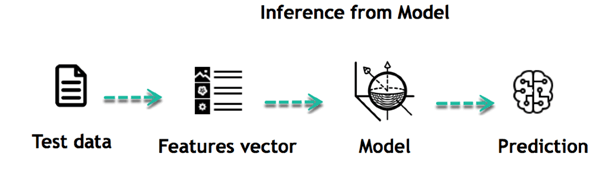
استنتاج Inference از مدل؛ بخش دوم در ماشین لرنینگ
وقتی مدل ساخته شد، این امکان به وجود میآید که با دادههای جدید تستش کنید تا بدانید چقدر قوی و قابل تکیه است. دادههای جدید را در قالب یک بردار ویژگی (Feature Vector) و به عنوان ورودی، به مدل میدهید تا به شما یک پیشبینی بدهد.
این قسمت در آموزش یادگیری ماشین بسیار هیجانانگیز است. چون بدون نیاز به آپدیت کردن قوانین یا منظم کردن دوبارهی مدل، شما میتوانید از آن مدل، برای استنتاج و نتیجهگیری از دیتای جدید استفاده کنید. هر بار هم که الگوریتم در استخراجِ نتایجِ درست، بهتر میشود، از همان نتایج دوباره برای عملکرد بهترش در مورد دادههای جدید، استفاده میکند.
در آموزش یادگیری ماشین باید به خوبی نحوه عملکرد هر دو بخش یادگیری و استنتاج را بیاموزید.
مراحل یادگیری ماشین
مراحل یادگیری ماشین به طور خلاصه در قدمهای زیر و به ترتیب ذکر شده است:
- بیان مساله (Define a question)
- جمعآوری دیتا (داده) (Collect data)
- بصریسازی دیتا (Visualize data)
- مرتبسازی الگوریتم (Train algorithm)
- آزمایش الگوریتم (Test the Algorithm)
- جمعآوری بازخورد (Collect feedback)
- تصحیح الگوریتم (Refine the algorithm)
- ادامه چرخه از مراحل ۴ تا ۷ تا زمانی که به نتایج رضایت بخش و مدل برسیم
- استفاده از مدل برای پیشبینی
آموزش الگوریتم های یادگیری ماشین
یادگیری ماشین ML الگوریتمهای بسیار زیادی دارد اما میتوان آنها را در سه دسته اصلی زیر طبقهبندی کرد که در ادامه به طور کامل و با مثال توضیح داده شدهاند:
- یادگیری با نظارت (Supervised ML)
- یادگیری بی نظارت (Unsupervised ML)
- و یادگیری تقویتی (Reinforcement ML)
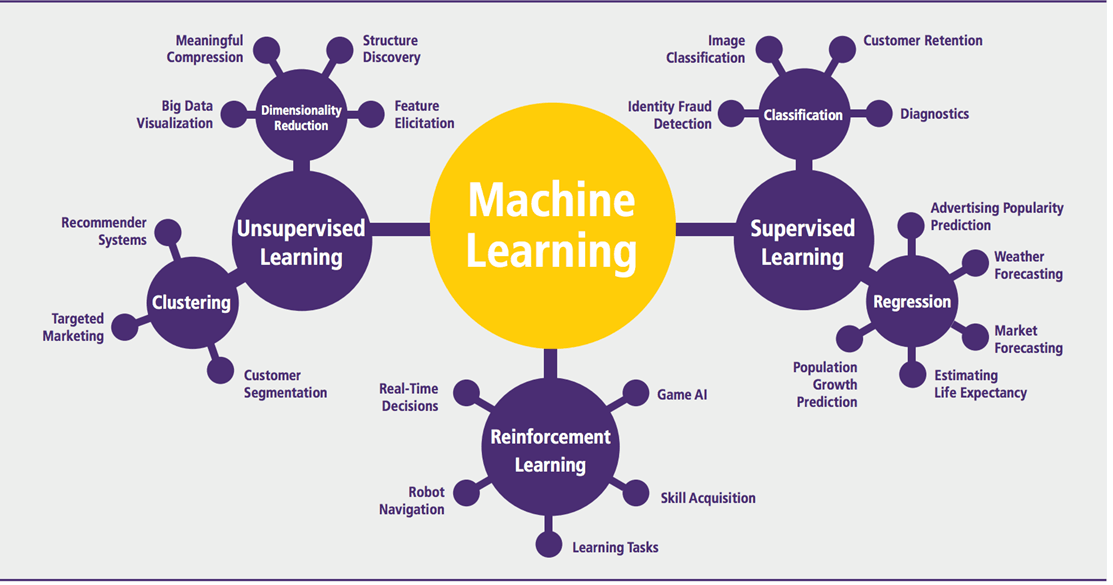
یادگیری با نظارت Supervised ML چیست؟
در یادگیری نظارت شده (Supervised ML)، الگوریتمها از دادههای مرتب شده و بازخوردهای انسانها استفاده میکنند تا ارتباط بین ورودیها و خروجیها را یاد بگیرند.
چه زمانی از یادگیری با نظارت Supervised ML استفاده میکنیم؟
شما زمانی میتوانید از الگوریتمهای یادگیری نظارت شده استفاده کنید که نوع دادههای خروجی، شناخته شده هستند و الگوریتم میتواند نتیجه دیتای جدید را پیشبینی کند.
به عنوان مثال شما تصاویرِ تعدادی موز و سیب را با برچسبِ موز و سیب به الگوریتم میدهید و ماشین یاد میگیرد که سیب و موز چه شکلی دارند. سپس تصویرهای سیب و موز بدون برچسب (Label) را به عنوان ورودی به ماشین میدهید و او خود تشخیص میدهد کدام سیب است و کدام موز و به آنها برچسب درست میزند.
انواع یادگیری با نظارت Supervised ML
الگوریتمهای یادگیری با نظارت در دو نوعِ اصلی زیر، طبقهبندی میشوند:
۱. دسته بندی یا Classification در یادگیری ماشین
در دسته بندی یا Classification، دیتای ورودی براساس چند برچسب، از هم جدا شده و در دستههای مجزا قرار میگیرد. برای آموزش یادگیری ماشین در این نوع به مثال زیر توجه کنید.
مثال طبقه بندی در ماشین لرنینگ
فرض کنید میخواهید جنسیت مشتریان یک شرکت تجاری را پیشبینی کنید. مشتریان شما فقط میتوانند زن یا مرد باشند، پس خروجی مشخص بوده و این الگوریتم از نوع یادگیری نظارت شده است.
هدف شرکت هم، تعیین کردن احتمالِ زن یا مرد بودن هر مشتری، بر اساس اطلاعات جمعآوری شده و طبقهبندی کردن مشتریان در دو گروه مجزای جنسیتی است. پس نوع الگوریتم، دستهبندی است.
برای این کار، ابتدا اطلاعات مشتریان را مثل؛ قد، وزن، شغل، حقوق، سبد خریدشان و… از دیتابیس خود جمعآوری میکنید تا الگوریتم الگوها را از دیتا تشخیص دهد و یک مدل بسازد.
زمانی که مدل ساخته شده و یاد گرفت چطور زن یا مرد بودن را تشخیص دهد، شما میتوانید از دادههای جدید برای پیشبینی استفاده کنید. برای مثال، شما اطلاعات جدیدی را از یک مشتری ناشناس دریافت کردید و میخواهید بدانید او زن است یا مرد، اگر مدل پیشبینی کرد ۷۰درصد مرد، به این معناست که الگوریتم ۷۰درصد اطمینان دارد که مشتری مرد است و ۳۰درصد احتمال میدهد او زن است.
۲. رگرسیون Regression [به همراه مثال]
زمانی از مدلِ رگرسیون Regression استفاده میشود، که ماشین برای پاسخ، به دنبال یک مقدار پیوسته و متوالی باشد. به عنوان مثال یک تحلیلگر مسائل مالی، نیاز دارد ارزش یک سهام را بر اساس چند ویژگی مثل سهم، عملکرد گذشته سهام، شاخصهای اقتصاد کلان و…. پیشبینی کند. سیستم باید به روشی آموزش ببیند که قیمت سهام را با کمترین خطای ممکن تخمین بزند.
معروف ترین الگوریتم های یادگیری نظارت شده Supervised ML
- رگرسیون خطی (Linear regression)
- رگرسیون لجستیک (Logistic regression)
- درخت تصمیم (Decision Tree)
- ماشین بردار پشتیبانی (Support Vector Machines – SVM)
- دسته بندی کننده بیزی ساده (Naive Bayes)
- k نزدیکترین همسایگی (K-nearest neighbor)
- جنگل تصادفی (Random Forest)
- گرادیان تقویتی (Gradient Boosting)
۱۱ کاربرد عملی یادگیری نظارت شده Supervised ML
در آموزش یادگیری ماشین (Machine Learning) بسیار مهم است که شما از موارد کاربرد هر الگوریتم در دنیای واقعی آگاه باشید. به این ترتیب میتوانید با ذهن بازتری یادگیری ماشین را آموخته و از آن استفاده کنید.
موارد کاربرد یادگیری با نظارت Supervised ML به شرح زیر است:
- بیوانفورماتیک (Bioinformatics)
- ساختار کمی (Quantitative Structure)
- بازاریابی بانک اطلاعاتی (Database Marketing)
- تشخیص دست خط(Handwriting Recognition)
- بازیابی اطلاعات (Information Retrieval)
- یادگیری درجهبندی (Learning to Rank)
- استخراج اطلاعات (Information Extraction)
- تشخیص اشیاء در دید رایانهای (Object Recognition In Computer Vision)
- تشخیص نوری کاراکترها (Optical Character Recognition)
- تشخیص اسپم (Spam Detection)
- تشخیص الگو (Pattern Recognition)
- و ….
یادگیری بی نظارت Unsupervised ML چیست؟
در یادگیری نظارت نشده (Unsupervised ML)، الگوریتم بدون دادن یک خروجی واضح و روشن، تنها در دادههای ورودی، به دنبال الگوها، شباهتها و تفاوتها میگردد. مانند بررسی دیتای دموگرافیکِ (جمعیت شناختی) مشتریها مثل سن، جنسیت و موقعیت مکانی و… تا الگوها را بشناسد.
چه زمانی از یادگیری نظارت نشده Unsupervised ML استفاده کنیم؟
از یادگیری بی نظارت Unsupervised ML، زمانی که نمیدانید چطور دیتا را طبقهبندی کنید و میخواهید الگوریتم برای شما الگوها و دستهبندی دیتا را انجام دهد، میتوانید استفاده کنید. البته ماشین باید در ابتدا برنامهنویسی شود که چطور از دیتا یاد بگیرد.
مثال یادگیری بی نظارت
به عنوان مثال تصاویر موز و سیب را به همراه دیتای اولیه و ویژگیهایشان به ماشین میدهیم درحالیکه برچسبگذاری نشدهاند و ماشین هم تا به حال این تصاویر را ندیده است. در این حالت ماشین بر اساس خصوصیات و شباهتهایی که تصاویر با هم دارند، خودش سیبها و موزها را دسته بندی میکند.
انواع یادگیری بی نظارت Unsupervised ML
الگوریتمهای یادگیری نظارت نشده در دو نوعِ اصلی زیر، طبقهبندی میشوند:
خوشه بندی Clustering
خوشه بندی (Clustering) در موضوعاتی استفاده میشود که شما میخواهید گروههای اصلی در دادهها را کشف کنید. مثل گروهبندی مشتریها بر اساس رفتار خریدشان
پیوستگی Association
از یادگیری ماشین توسط مدل پیوستگی (Association)، زمانی استفاده میشود که شما میخواهید قوانینی که بخش عظیمی از دیتای شما را توصیف میکنند، کشف کنید. مثلا افرادی که کالای x را میخرند اغلب تمایل دارند کالای y را هم بخرند.
پرکاربردترین الگوریتمهای یادگیری نظارت نشده Unsupervised ML
- K-means Algorithm
- Apriori Algorithm
- Expectation–maximization algorithm (EM)
- Principal Component Analysis (PCA)
- الگوریتم k میانگینK-means Algorithm
- الگوریتم آپریوری Apriori Algorithm
- الگوریتم EM Expectation–maximization algorithm
- تحلیل مولفههای اصلیPrincipal Component Analysis (PCA)
۴ حوزه اصلی استفاده از الگوریتمهای نظارت نشده Unsupervised ML
از الگوریتمهای یادگیری نظارت نشده در موضوعات متنوعی استفاده میشود که به شرح زیر ملاحظه میکنید. آگاهی از این روشها نقش مهمی در آموزش یادگیری ماشین و درک بهتر آن دارد.
- تحلیل رفتار انسانها
- تجزیه و تحلیل شبکههای اجتماعی برای تشخیص گروههای دوستی
- بخشبندی بازار شرکتها بر اساس مکان جغرافیایی ، نوع صنعت و…
- سازماندهی خوشههای محاسباتی بر اساس فرایند و الگوهای رویداد مشابه
آموزش یادگیری تقویتی Reinforcement ML چیست؟
در این مرحله از آموزش یادگیری ماشین و الگوریتمهای آن، به آموزش یادگیری تقویتی Reinforcement ML میپردازیم. در الگوریتم تقویت شده Reinforcement ML، ماشین آموزش داده میشود که بر اساس دادههای موجود و ممکن، تصمیمی بگیرد. ماشین از هر تصمیمی که میگیرد، یک فیدبک یا بازخورد دریافت میکند که آیا تصمیم درست بوده است یا غلط و به این ترتیب هر بار یاد میگیرد که کدام تصمیم درست بود و در دفعات بعد در همان موقعیت، آن رفتار را تکرار میکند.
دلیل نامگذاری این یادگیری ماشین به تقویت شده یا تقویتی این است که عملکرد الگوریتم همواره با مراحل فیدبک و بازخورد تقویت میشود.
الگوریتم های یادگیری تقویتی Reinforcement ML
از ۴ مورد زیر، دو مورد اول معروفترین الگوریتم های یادگیری تقویتی محسوب میشوند:
- Q-Learning Algorithm
- State–action–reward–state–action Algorithm (SARSA)
- Deep Q Network Algorithm (DQN)
- Deep Deterministic Policy Gradient Algorithm (DDPG)
کاربرد یادگیری تقویتی Reinforcement ML
کاربرد یادگیری تقویتی بیشتر در حوزه بازیهای کامپیوتری (Video Games) و هوش مصنوعی است. مواردِ دیگرِ کاربرد یادگیری تقویت شده را به شرح زیر ملاحظه میکنید.
- مدیریت منابع در خوشههای رایانهای Resources management in computer clusters
- کنترل چراغ راهنمایی Traffic Light Control
- رباتیک Robotics
- پیکربندی سیستم وب Web System Configuration
- توصیههای شخصیسازی شده Personalized Recommendations
- یادگیری عمیق Deep Learning
مقایسه الگوریتم های یادگیری ماشین ، کدام را انتخاب کنیم؟
در مقایسه الگوریتم های یادگیری ماشین با هم و انتخاب مناسبترین الگوریتم باید حتما اهداف پروژه، نوع و حجم دادههای موجود و همچنین میزان زمانتان را مدنظر قرار دهید. چون همانطور که ملاحظه کردید، تعداد زیادی الگوریتم یادگیری ماشین وجود دارد که هر کدام برای هدفی مشخصی ساخته شده است.
در مثال زیر، هدف پیشبینی نوع گل از بین سه نوعِ مختلفِ قرمز، آبیِ روشن و آبیِ تیره است. این پیشبینی بر اساس اندازه، طول و عرضِ گلبرگ گلها است. در تصویر زیر نتیجه پیشبینی را از ۱۰ الگوریتم مختلف مشاهده میکنید. تصویر اول از سمت چپ دیتای اولیه است و مابقی نتیجه الگوریتمهاست.
همانطور که میبینید الگوریتمها، اطلاعات را گروهبندی کردهاند. در عکس دوم از سمت چپ، تمام نقاط در بخش بالایی تصویر در دسته گل قرمز قرار دارند، بخش وسط نشاندهنده گروهی از گلهاست که یا رنگ آبی روشن هستند یا الگوریتم درمورد رنگشان اطمینان ندارد و بخش پایین تماما به گلها با رنگ آبی تیره مربوط است.
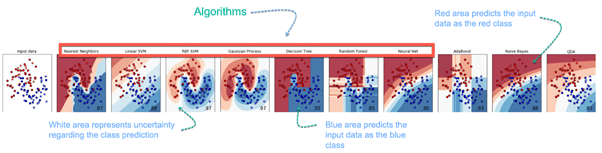
تصاویر دیگر هم نتایج طبقهبندی توسط الگوریتمهای دیگر را نشان میدهد، که با هم متفاوت هستند، پس انتخاب الگوریتمِ مناسب، متناسب با هدف پروژه، نوع و میزانِ دیتا بسیار مهم است.
یادگیری ماشین با پایتون: پایتون بهترین زبان برنامه نویسی برای Machine Learning است
پایتون (Python) بهترین زبان برنامه نویسی برای یادگیری ماشین است.
با اینکه شما میتوانید تقریباً از هر زبان برنامه نویسی برای نوشتن برنامههای مبتنی بر یادگیری ماشین استفاده کنید، اما چون نوشتن هر الگوریتم از ابتدا، فرایند وقت گیری است؛ به همین دلیل بهتر است از یک زبان برنامهنویسی که کتابخانههای از پیش ساخته شده (Pre-built Libraries) و فریمورکهای (Framework) خوبی داشته باشد، استفاده کنید. همچنین زبان برنامهنویسی مورد نظر باید به طور پیشرفتهای از علوم و مدلهای داده پشتیبانی کند.
در دوره استادی پایتون ما از پایه با بحث برنامه نویسی پایتون و دستورات این زبان برنامه نویسی قدرتمند آشنا می شویم.
دوره استادی پایتون (ورژن ۳) از پایه
چرا پایتون بهترین زبان برنامه نویسی برای یادگیری ماشین است؟
پایتون Python در حال حاضر محبوبترین زبان برای ML است. چون:
فریم ورک ها و کتابخانه های پایتون مناسب برای ماشین لرنینگ
بسیاری از فریم ورکها و کتابخانه های پایتون به طور کاملا ویژهای، برای هوش مصنوعی و یادگیری ماشین کاربرد دارند.
لیستی از این کتابخانهها را مشاهده میکنید:
- Keras : یک کتابخانه منبع باز و پرکاربرد در آزمایش شبکههای عصبی عمیق
- TensorFlow: کتابخانههای رایگان و متنبازی که در شبکههای عصبی و یادگیری عمیق کاربرد دارند.
- Scikit-Learn: کتابخانه سایکیت لرن، الگوریتمهای مختلف طبقهبندی، رگرسیون و خوشهبندی را دارا است.
- Seaborn: سیبورن برای انجام بصریسازی در یادگیری ماشین مورد استفاده قرار میگیرد.
- Matplotlib: مت پلات لیب هم یک کتابخانه قدرتمند برای بصریسازی دادهها به کمک انواع نمودارها است.
- NumPy: نام پای یک کتابخانه معروف برای انجام تحلیلهای عددی مثل محاسبه میانگین و… است.
- Pandas: پانداس هم برای پردازش انواع فایلهای CSV مورد استفاده قرار میگیرد.
کار با پایتون ساده است
پایتون ساختار و دستورات بسیار سادهای دارد که باعث شده است زبان برنامهنویسی محبوب دانشجویان و برنامهنویسان باشد. کدهای پایتون بسیار شبیه به زبان انسان است و این امر کار را به مراتب سادهتر کرده است.
پایتون رو به رشد و فراگیر است
شرکتهای بزرگی از زبان برنامهنویسی پایتون استفاده کردهاند؛ همچون گوگل، فیسبوک، اینستاگرام و… . حتی مسئولیت ایجاد کتابخانههایی مثل Keras در پایتون، برای آموزش یادگیری ماشین، با گوگل بوده است.
همچنین منابع اینترنتی بسیار قویای برای آموزش ماشین لرنینگ با پایتون، منتشر شده است؛ که به روز هستند و کمک بزرگی به توسعه و البته افزایش محبوبیت این زبان کردهاند.
۱۰ زبان برنامه نویسی محبوب برای ML در گوگل ترندز ۲۰۲۰
اگر میخواهید بدانید بعد از پایتون کدام زبانهای برنامه نویسی برای یادگیری ماشین، ترند هستند؛ به لیست زیر که با توجه به تحقیق انجام شده در گوگل ترندز و بررسی بیشترین کلمات سرچ شده است، دقت کنید:
- Python
- C++
- Java
- JavaScript
- C#
- R
- Julia
- GO
- TypeScript
- Scala
۶ چالش اصلی و محدودیت در یادگیری ماشین
با اینکه یادگیری ماشین کار بسیاری از صنعتها را راحت کرده است، اما استفاده از این تکنولوژی چالشها و محدودیتهایی هم دارد. از جمعآوری و تحلیل دادههای مناسب گرفته تا پاک کردن دیتای نویز که شما در آموزش یادگیری ماشین باید اشراف کاملی به این موارد داشته باشید.
-
جمعآوری دادهها و طریقۀ مصرف آنها Data Collection & Usage
چالش اصلی در یادگیری ماشین، نبود دیتا یا نبود تنوع در مجموعه دادهها است. اگر دیتا در دسترس یک ماشین نباشد، نمیتواند یاد بگیرد. همچنین دادههایی که تنوع ندارند، باعث میشوند زمان زیادی طول بکشد تا ماشین یاد بگیرد. یک ماشین به ناهمگنی و تنوع نیاز دارد تا به یک بینش و درک در رفتار برسد. خیلی به ندرت پیش میآید که یک الگوریتم، بتواند اطلاعات درستی ارائه کند زمانی که تنوع دیتای کمی دارد.
توصیه میشود که حداقل ۲۰ مشاهده برای هر گروه داشته باشید تا به یادگیری ماشین کمک کند. وگرنه این محدودیت منجربه ارزیابی و پیشبینی ضعیف ماشین میشود.
از کجا بدانیم کدام داده برای الگوریتم یادگیری ماشین ما مناسبتر است؟
قبل از هرچیزی اهداف الگوریتم را بنویسید و مشخص کنید چه نوع اطلاعاتی میتواند برای رسیدن به آن اهداف مفید باشد. باید توجه کنید که صرفا جمعآوری دیتا فقط فضای ذخیرهی شما را پر میکند. شما باید بدانید به چه نوع دادهای نیاز دارید و چطور قصد استفاده از آن را دارید. بنابراین به عنوان مثال؛ اگر میخواهید تصمیم بگیرید کدام رستوران را انتخاب کنید، نیازی به پیش بینی وضعیت هوا برای آن روز ندارید (مگر اینکه بخواهید روی تراس بنشینید!).
جمعآوری هر دیتای با ربط و بیربطی فقط باعث طولانیتر شدن فرایند یادگیری ماشین و متعاقبا، دیرتر رسیدنِ شما به نتیجه میشود. پس هدف و طریقۀ مصرف دیتا فراموش نشود و بر آن اساس بردار ویژگی خود را مشخص کنید.
-
امنیت Security
امنیت سایبری یکی از موضوعات داغ این روزها است. چون با در دست داشتن اطلاعات شخصیِ بسیاری از افراد، میتوان افکار عمومی را به سمت یک تصمیم، جهتدهی کرد یا تغییر جهت داد. در واقع موضوع، استفاده غیرقانونی از دادههای جمعآوری شده است.
بنابراین هنگام جمعآوری اطلاعات، باید مطمئن شوید که قانون را نقض نمیکنید و همچنین باید اطمینان حاصل کنید که رضایت افراد برای جمع آوری دادهها، گرفته شده است.

پیشنهاد دانشیار آی تی به شما
افزایش امنیت شبکه بیسیم خانگی
خواندن مطلب
-
اعتبار سنجی داده ها Data Validation
وقتی دادههای ورودی، از چندین منبع باشد، باید به صحت و اعتبار دادههای خود دقت کنید. آیا اطلاعاتی وجود دارد که بتواند به سیستم آسیب بزند؟ در این حالت، الگوریتمهای یادگیری ماشین نیمه نظارت شده با خودکار کردنِ روندِ برچسب زدن میتوانند کمک کنند. آنها میتوانند وارد دادههای بدون برچسب شوند و آنها را با نمونههای موجود، که برچسبگذاری شدهاند، مقایسه کنند.
-
الگوریتم های درست Right Algorithms
انتخاب الگوریتم درست یکی از چالشهای اساسی ML است. این موضوع را پیشتر هم توضیح دادیم که هر مدلِ یادگیری ماشین، یک هدف دارد و برای انجام کارهای خاصی طراحی شده است.
به عنوان مثال، یک الگوریتمِ نظارت نشده، نمیتواند دادههای شما را به درستی برچسبگذاری کند زیرا هدف اصلی آن جستجوی الگوها است. پس قبل از اجرای ML، یک بار دیگر، انتظارات خود از این فناوری و هدف نهاییتان را بنویسید.
-
مجموعه داده برای آموزش Training Dataset
هنگامی که شما الگوریتم یادگیری ماشینِ خود را آموزش میدهید، به یک دیتاست (Data Set) یا مجموعه داده آموزشی Training Dataset خوب و بزرگ نیاز دارید، تا الگوریتم بتواند از روی آن، الگوها، اطلاعات و رفتار درست را شناسایی کند. اگر مجموعه دادۀ آموزشی شما کوچک باشد، نتایج ممکن است درست نباشد.
در واقع استفاده از الگوریتمهای یادگیری ماشین برای دیتاسِتهای کوچک، اکثرا مقرون به صرفه نیست، بنابراین از حجمِ اطلاعاتِ معتبر مطمئن شوید و بعد از یادگیری ماشین استفاده کنید.
دیتاست یا مجموعه داده آموزشی را برای الگوریتم چگونه جمع آوری کنیم؟
دیتا ست یا مجموعه داده آموزشی را میتوانید از حساب گوگل آنالیتیکس شرکت جمعآوری یا خریداری کنید؛ اما موضوع مهم همانطور که در بخش قبل هم گفتیم این است که حتما باید این اطلاعات قانونی، اعتبارسنجی شده و متناسب با هدف شما باشند.
-
داده های نویزی Data Noise
داده های نویزی و اخلالگر (Data Noise) به دادههای گفته میشود که هیچ ارتباطی با هدف الگوریتمِ یادگیری ماشین ندارند. به عنوان مثال، اگر به دنبال رستورانی هستید که سس خاصی را سرو میکند، داشتن اطلاعات از منوی رستورانها برای شما مهم است اما اگر هدفتان پیدا کردن یک رستوران خوب در حومه شهر است، نام آشپز رستورانها برای شما غیرضروری خواهد بود.
دادههای نویزی میتوانند شامل اطلاعات ناقص، دادههای بیاهمیت، بیتهای غیر عادی و اطلاعات غیر قابلِ شناسایی باشند.
این موضوع به این دلیل مهم است؛ که به گفته محققان آی بی ام IBM، “طبق اصل پارتو: ۸۰٪ از وقتِ با ارزش یک متخصصِ داده صرفِ پیدا کردن، پاکسازی و سازماندهی دادهها میشود و تنها ۲۰٪ از زمان او صرف تجزیه و تحلیل دادهها میشود.”چون دادههای نویزی، عملکرد الگوریتمِ یادگیری ماشین را پایین میآورند و باعث میشوند نتایج خیلی دقیق نشوند.
کاربردهای یادگیری ماشین و ۷ حوزه ای که پیشرفت خود را مدیون استفاده از آن است
با اینکه استفاده از یادگیری ماشین، چالشها و محدودیتهای خود را دارد اما به یاد داشته باشید که کاربردهای یادگیری ماشین در علوم مختلف، باعث پیشرفت بسیار زیادی شده است. چون یادگیری ماشین دانشی است که هر روز به سرعت رشد میکند و تا الان هم میتوان گفت همۀ حوزهها را فتح کرده است.
در ادامۀ مقاله به معرفی ۷ حوزهای که پیشرفت خود را مدیون به کارگیری یادگیری ماشین هستند میپردازیم تا شما هم با این آموزش یادگیری ماشین، در هر حوزهای که هستید با ایدههای بهتر، یک تحول اساسی خلق کنید.
-
یادگیری ماشین در اقتصاد و خدمات مالی و بانکداری Banking & Financial Services
یادگیری ماشین در اقتصاد و خدمات مالی و بانکداری، به این دلیل که این حوزه با دادههای عددی زیادی سر و کار دارد، بسیار پرکاربرد است. یکی از بهترین استفادههای الگوریتمهای یادگیری ماشین در این حوزه، تشخیص ناهنجاری و جلوگیری از کلاهبرداری است. یادگیری ماشین، علاوه بر محافظت از مشتریهای پر ریسک و جلوگیری از کلاهبرداری یا دستکاری، به شناسایی فرصتهای سرمایه گذاری و تجارت هم کمک میکند.
-
کاربرد یادگیری ماشین در مدیریت و دولت Government
یادگیری ماشین و دادهکاوی (Data Mining) میتوانند به دولت در مدیریت، امنیت عمومی و صنایع همگانی کمک کنند. یکی از زمینههای بسیار مهم در این مورد، کمک به کارایی انرژی است که منجر به حداقل رساندن هزینهها و بار مالی، میشود.
در ضمن الگوریتمهای یادگیری ماشین، در تشخیص چهره و در جهت نظارت و جلوگیری از جعل هویت هم کمک میکنند.
-
یادگیری ماشین در پزشکی و بهداشت و درمان Healthcare
یادگیری ماشینی در پزشکی برای پیش بینی موضوعات مرتبط با بهداشت و درمان یکی از ترندهایی است که رشد صعودی بسیار سریعی دارد. به وسیلۀ دستگاهها و سنسورهای پوشیدنی، دادههای بیمار میتواند در اختیار الگوریتمهای یادگیری ماشین و به طور لحظه به لحظه قرار بگیرد که به نجات جان آنها کمک زیادی میکند.
همچنین آنالیز دادههای بزرگ Big data و الگوریتمهای یادگیری ماشین، میتوانند به کمک هم و با تحلیل روند و شناسایی موقعیتهای قرمز، به تشخیص و درمان، بسیار کمک کنند. در ضمن از الگوریتمهای یادگیری ماشین برای پردازش تصویر در شکلگیری بافتهای غیر طبیعی اندامهای انسان استفاده میشود، تا به تشخیص زودهنگام سرطان برسند.
-
کاربرد یادگیری ماشین در صنعت ، کسب و کارها و تجارت الکترونیک Retail & Ecommerce
صنعت، کسب و کارها و تجارتهای الکترونیک، به کمک الگوریتمهای یادگیری ماشین و با استفاده از سیستم پیشنهاددهی (recommendation systems) میتوانند تجربهی لذتبخشتری برای مشتریها ایجاد کنند.
همچنین کسب و کارها میتوانند با جمعآوری و آنالیز دیتا، تجربه خرید هر فردی را شخصیسازی کنند و همچنین از این دادهها برای اجرای کمپینهای بازاریابی، بهینهسازی قیمتها و آگاهی از نگرش مشتری استفاده کنند.
-
یادگیری ماشین و هوش مصنوعی در صنعت نفت ، گاز و انرژی Oil, Gas & Energy Sector
با استفاده از الگوریتمهای دسته بندی (classification) یادگیری ماشین و هوش مصنوعی، تجزیه و تحلیل مواد معدنی موجود در زمین، یافتن منابع انرژی جدید و … مقرون به صرفهتر شده است. همچنین از الگوریتمهای یادگیری نظارت نشده برای تشخیص الگوهایی مثل خرابی سنسور یا حل نقصهایی که پیش از این دیده نمیشد، استفاده میشود.
-
یادگیری ماشین در صنعت حمل و نقل و خودرو Transportation & Automotive
بهترین مسیر کدام است؟ چگونه ظرفیت رفت و آمد در خیابانها را افزایش دهیم؟ چگونه سیستم نورپردازی شهر را بهینه کنیم؟ به همه این سؤالات میتوان با کمک الگوریتمهای یادگیری ماشین پاسخ داد.
آیا تابحال از اپلیکیشن بَلَد، نشان یا وِیز (Waze) استفاده کردهاید و از توانایی آن برای پیدا کردن بهترین مسیر لذت بردهاید؟ بله، این همان کارکردِ یادگیری ماشینی است. آموزش یادگیری ماشین برای شرکتهایی که با تحویلهای فوری، حمل و نقل عمومی و رفت و آمد سروکار دارند، بسیار مهم است.
همچنین اتومبیلهای بدون راننده، هم در مبحث رانندگی و هم سیستم اطلاع رسانی خودکارِ انرژی، از الگوریتمهای یادگیری ماشین استفاده کردهاند.
-
یادگیری ماشین در بازاریابی و تبلیغات Advertising Technologies) ADTECH)
کسب و کارهای ADTECH که کار اصلی آنها تبلیغات هوشمند است، به شدت روی الگوریتمهای یادگیری ماشین تکیه کردهاند. به این دلیل که فناوری تبلیغاتی، یکی از مهمترین صنعتهای بیگ دیتا است.
دقیقا مثل کاربرد یادگیری ماشین در تجارت الکترونیک برای شخصیسازیِ تجربه هر مشتری، تبلیغات نیز توسط این تکنولوژی شخصیسازی میشود و به این ترتیب بازاریابی هدفمندتر میشود.
در این بین مشتریها با تبلیغاتی که دوست دارند، مورد هدف قرار میگیرند (بر اساس توصیههای موتورهای جستجو و ترجیحات خود کاربر)، تبلیغ کننده هم چون تبلیغش به دست افراد مناسب رسیده است، راضی است و در این بین سیستمِ تبلیغ کننده هم پول خود را دریافت میکند و به این ترتیب همه راضی هستند.
چرا یادگیری ماشین اهمیت دارد؟
آیا آموزش یادگیری ماشین تصمیم درستی است؟ زمان با ارزشترین دارایی است و استفاده از یادگیری ماشین، زمانِ بیشتر و تجربهی لذتبخشتری برای همه فراهم میکند.
یک مشاور املاک ماهر میتواند قیمت هر خانهای را بر اساس تجربه و شناختی که از بازار دارد و با در نظر گرفتن تمامِ متغیرهای خانه، همسایه، اقتصاد، محیط و… تخمین بزند. او برای این یادگیری و تخصص، تمامِ عمرش را صرف کرده است.
اما یک ماشین هم میتواند آموزش ببیند که دقیقا همان قیمت را پیشبینی کند ولی با دقتی بیشتر، در زمانی کمتر و با بهبودِ عملکرد دائمی و به این ترتیب انجام کارهایی که برای انسان طاقتفرسا یا غیرممکن است، به راحتی ممکن میشود.
به همین دلیل آموزش یادگیری ماشین یک راهکار قطعی برای رشد در عصر دیجیتال به شمار میآید.
جمع بندی آموزش یادگیری ماشین
- در این مقاله از دانشیار آی تی، نقشه راه آموزش یادگیری ماشین را آموختیم.
- مفهوم یادگیری با نظارت، یادگیری بی نظارت و یادگیری تقویتی را درک کردیم.
- علاوه بر آشنایی با مهمترین الگوریتمهای هر کدام از انواعِ یادگیریها، زمینهی کاربردِ آنها را در دنیای واقعی متوجه شدیم.
- با چالشها و مزایای یادگیری ماشین آشنا شدیم.
- و فهمیدیم چرا زبان برنامهنویسی پایتون، بهترین زبان برای یادگیری ماشین است.
به نظر شما در ایران بهترین حوزه برای استفاده از یادگیری ماشین چیست؟ کدام شرکتها در استفاده از یادگیری ماشین پیشتاز هستند؟ جواب سوالات را در قسمت نظرات این مقاله بنویسید و با ما در ارتباط باشید.
نویسنده: نگار سلیمانی
پیشنهاد دانشیار آی تی برای آموزش یادگیری ماشین با پایتون
دوره جامع یادگیری ماشین و داده کاوی با پایتون؛ که یک دورۀ پروژه محور است و طی ۱۸ ساعت آموزش با ۲۲ پروژۀ عملی، به شما مباحث لازم و اساسی را آموزش میدهد.
![]() دورههای مرتبط در دانشیار آی تی
دورههای مرتبط در دانشیار آی تی



